Performance Estimation
このページでは、MLdebuggerを用いてGTが付与される前の運用データにおける性能変化を推定し、劣化要因を特定するための流れを説明します。
前提知識
推論ログ収集は Log Monitoring、評価結果の準備は Evaluator を参照してください。
概要
Performance Estimationは、既存の評価結果を基準として運用時の推定エラー傾向を継続監視し、性能の変化を早期に検知するためのユースケースです。各画面ごとに以下の情報が予測されます。
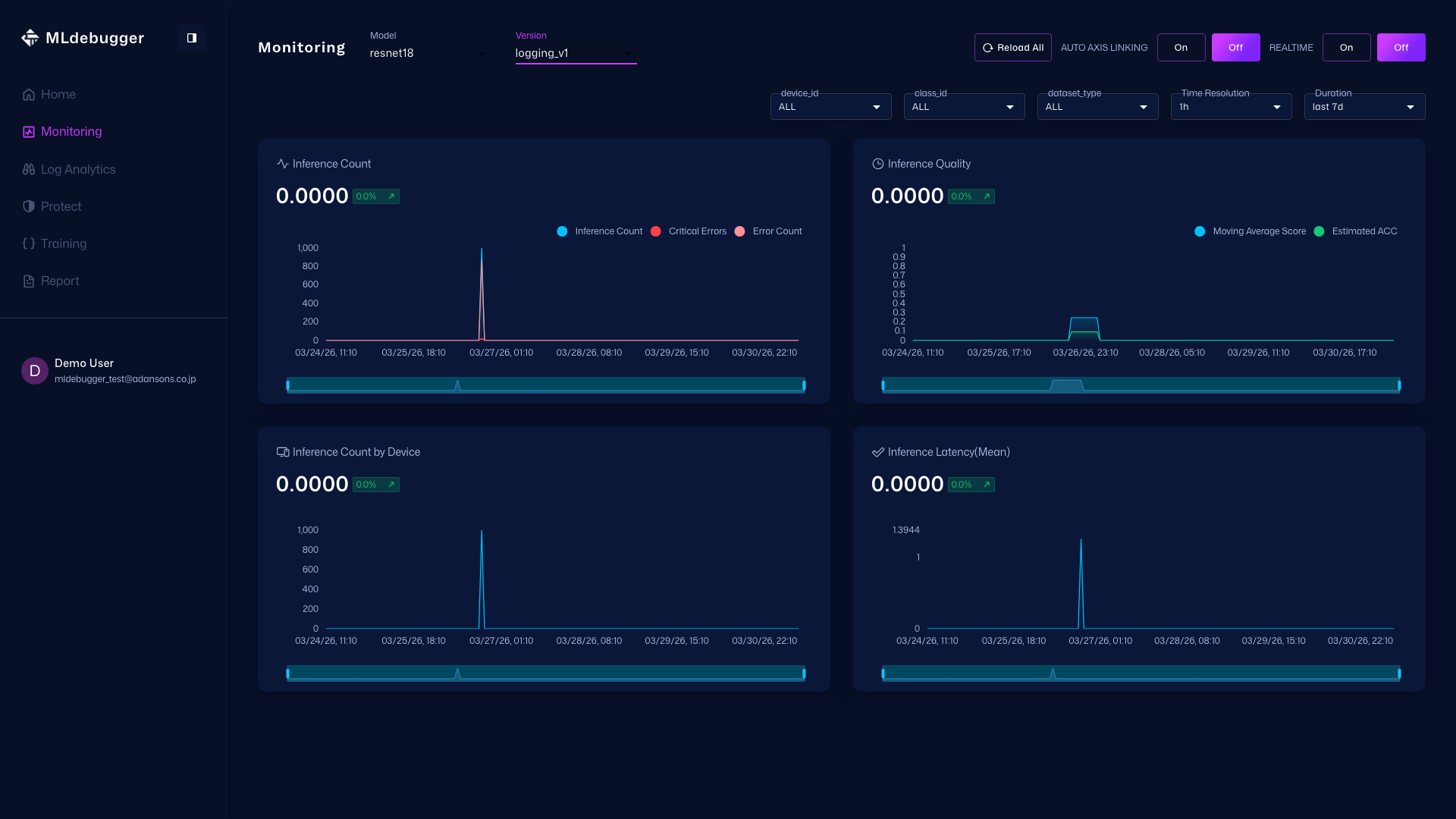
Monitoring
| Plotエリア | 予測される情報 |
|---|---|
| Inference Count Window | Estimated Error Count |
| Estimated Critical Error Count | |
| Moving Average Accuracy | Estimated ACC |
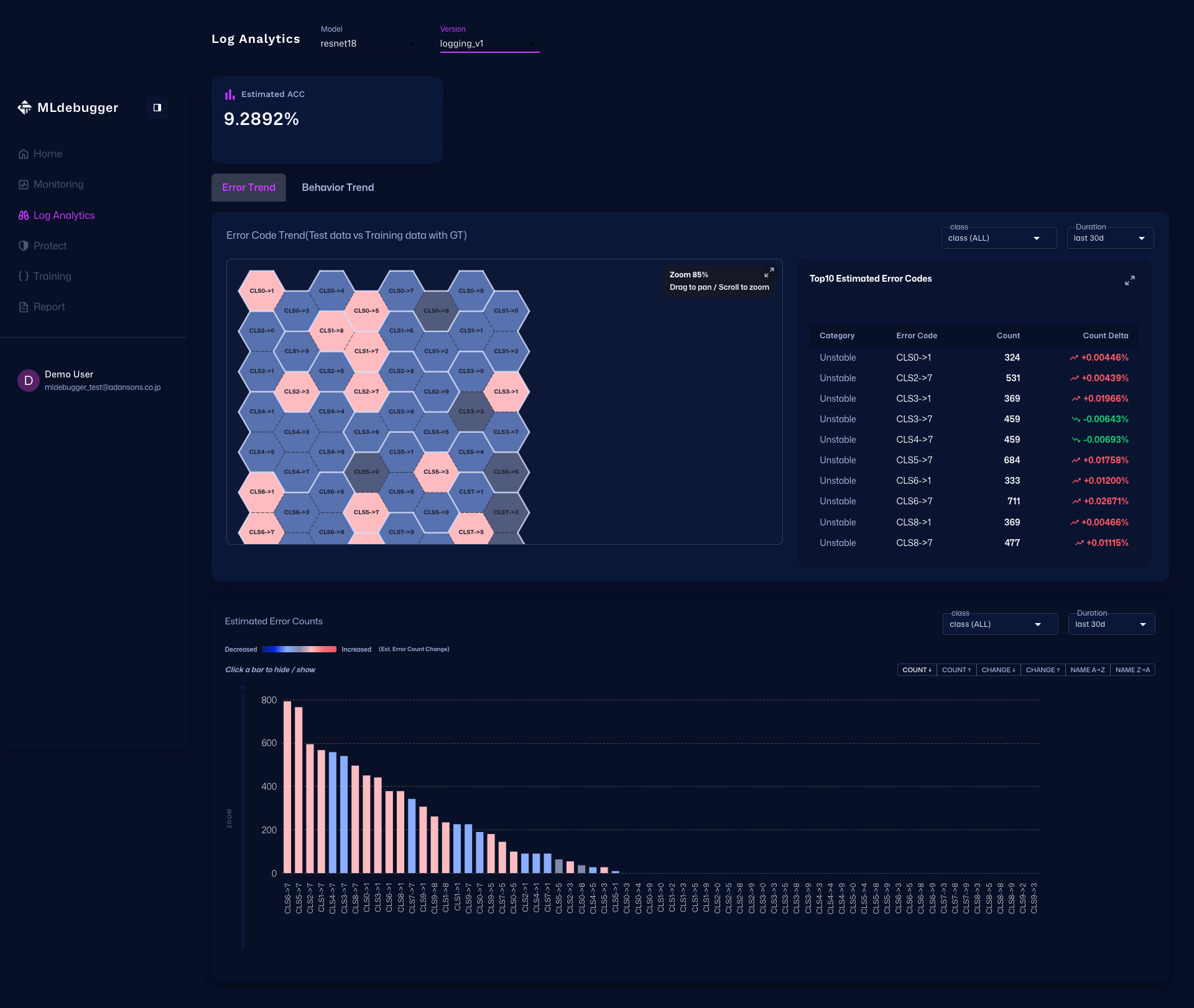
Log Analytics
| タブ | セクション | 予測される情報 |
|---|---|---|
| Error Mapタブ | Error Map内 | Estimated Error Code単位でのCount |
| Estimated Error Codes内 | Estimated Error ProbabilityとScoreから算出されるCategory | |
| Estimated ACC | ||
| Estimated Error Trends内 | Durationに応じたEstimated Error Code | |
| Heatmapタブ | Delta Heatmap内 | Estimated Error ProbabilityとScoreから算出されるCategory |
| GTありの際のError Countと、GTなしの運用データにおけるEstimated Error Countの差分ヒートマップ | ||
| Count Heatmap内 | Estimated Error ProbabilityとScoreから算出されるCategory | |
| Log(GTなしの運用データ)のEstimated Error Countと、Train(GTありの際)のError Countのヒートマップ | ||
| Error Rate Heatmap内 | Estimated Error ProbabilityとScoreから算出されるCategory | |
| Log(GTなしの運用データ)とTrain(GTありの際)について、ヒートマップ全体に対する各binのエラー比率(Estimated Error Rate / Error Rate)を比較するヒートマップ |
Performance Estimationワークフロー
基準評価の準備からモニタリング分析、異常検知までの手順を説明します。
STEP 1: 基準となる評価結果を用意する
まず、運用ログと比較するための評価結果を固定し、参照するmodel_nameと、version_nameを決めます。ここでは、model_name="resnet18"と、version_name="logging_v1"を使用して説明を行います。
STEP 2: 運用ログを収集し Error Estimation
この節では、推論ログに推定情報を付与できる設定で収集を開始する流れを整理します。
STEP 3: Monitoring でトレンドを確認する
この節では、推論数や推定エラー関連指標の時系列変化から異常兆候を検知する見方を説明します。
STEP 4: Log Analytics で異常の集中点を特定する
この節では、Error Map と Issue List を使って問題が集中する条件や傾向を具体化します。
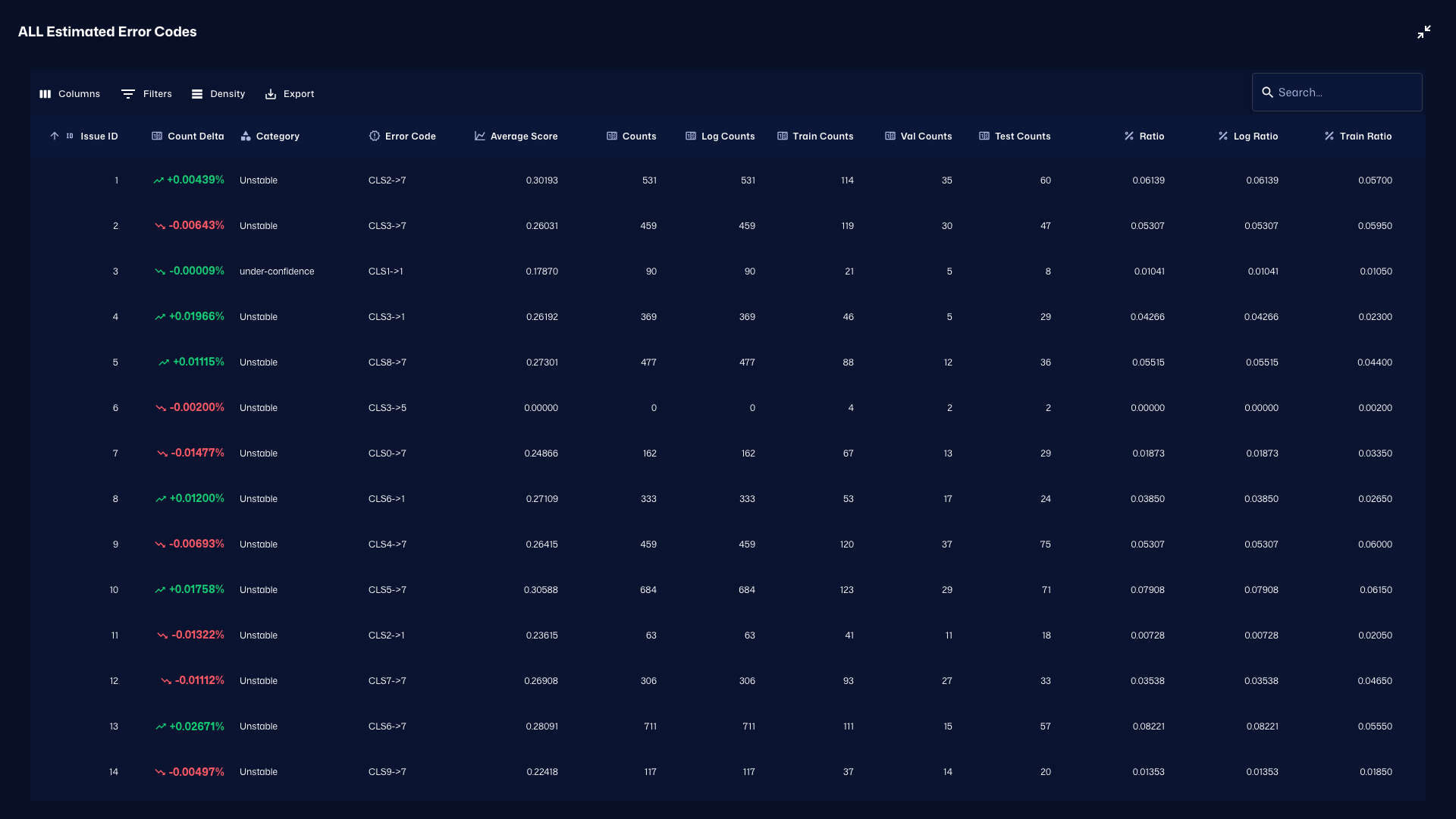
STEP 5: 改善アクションに落とし込む
この節では、推定結果に基づいて再学習・データ収集・しきい値調整などの次アクションを決定します。
ベストプラクティス
この節では、比較対象期間の選び方と継続監視時の確認ポイントを定義して解釈の一貫性を保ちます。
Active Learning / DataFilter との使い分け
この節では、Performance Estimationで異常を検知し、DataFilterで収集対象データを絞り込む役割分担を示します。
次のステップ
この節では、GUIの操作詳細は Monitoring と Log Analytics、SDK実装は Log Monitoring を起点に進めます。