Logging
このガイドでは、MLdebugger SDKを使用して運用時の推論ログを収集し、モニタリングする方法を説明します。
概要
Loggingフローは、本番環境での推論結果をリアルタイムで収集し、Webアプリでモデルの健康状態を監視するためのワークフローです。
STEP 1で使用するLoggerクラスはタスクによって異なります:
| タスク | Loggerクラス |
|---|---|
| Classification | ClassificationLogger |
| Object Detection | ObjectDetectionLogger |
| 3D Object Detection | ObjectDetection3DLogger |
前提条件と利用可能な機能
Loggingは Tracing + Evaluation の完了状況によって、利用可能な機能が異なります。
| 条件 | 利用可能な機能 |
|---|---|
| Tracing + Evaluation 未完了 | 基本メトリクスのみ(推論数、統計量など) |
| Tracing + Evaluation 完了済み | 基本メトリクス + Error Estimation機能(エラー確率推定、Issue Category分類) |
段階的な導入
まずはTracing + Evaluationなしで基本的なモニタリングを開始し、後からEvaluationを実行してError Estimation機能を有効化することも可能です。
STEP 1: Loggerの初期化
from ml_debugger.monitoring import ClassificationLogger
logger = ClassificationLogger(
model, # 本番環境のモデル
model_name="resnet18", # Tracerで使用したmodel_name
version_name="v1", # Tracerで使用したversion_name
result_name="resnet18_v1_classification_v1_20251219", # 評価結果のresult_name
)
from ml_debugger.monitoring import ObjectDetectionLogger
logger = ObjectDetectionLogger(
model, # Object Detectionモデル
model_name="faster_rcnn", # Tracerで使用したmodel_name
version_name="v1", # Tracerで使用したversion_name
result_name="faster_rcnn_v1_od_v1_20251219", # 評価結果のresult_name
)
NMSパラメータ(score_thresh, iou_thresh, max_detections_per_image)もオプションで指定可能です。未指定時はモデルから自動推定されます。
from ml_debugger.monitoring import ObjectDetection3DLogger
logger = ObjectDetection3DLogger(
model, # 3D Object Detectionモデル
model_name="centerpoint", # Tracerで使用したmodel_name
version_name="v1", # Tracerで使用したversion_name
result_name="centerpoint_v1_od3d_v1_20251219", # 評価結果のresult_name
)
NMSパラメータ(score_thresh, iou_thresh, max_detections_per_frame)もオプションで指定可能です。未指定時はモデルから自動推定されます。
result_nameの役割
result_nameを指定することで、Loggerは評価結果に基づいてエラー確率やIssue Categoryを推定できます(Error Estimation機能)。
指定しない場合は、推論数やレイテンシなどの基本メトリクスのみが収集されます。
result_nameは省略可能で、後からTracing + Evaluationを実行して有効化することも可能です。
STEP 2: 推論ログの収集
本番環境での推論時にログを収集します。
import torch
for image in production_dataloader:
image = image.to(device)
# Loggerを通して推論を実行
predictions = logger(image)
# 推論結果を使用(通常の処理を続行)
process_predictions(predictions)
通常の推論と同じ使用感
Loggerはモデルをラップしているため、通常の推論と同じように使用できます。 内部で自動的にログが収集され、APIサーバーに送信されます。
3D Object Detectionの入力形式
3D Object Detectionでは、入力データにdict形式(points, img 等)を使用します。
詳細は Tracing + Evaluation の3D Object Detectionタブを参照してください。
STEP 3: Webアプリでのモニタリング
収集されたログは app.adansons.ai のWebアプリで確認できます。
操作手順
-
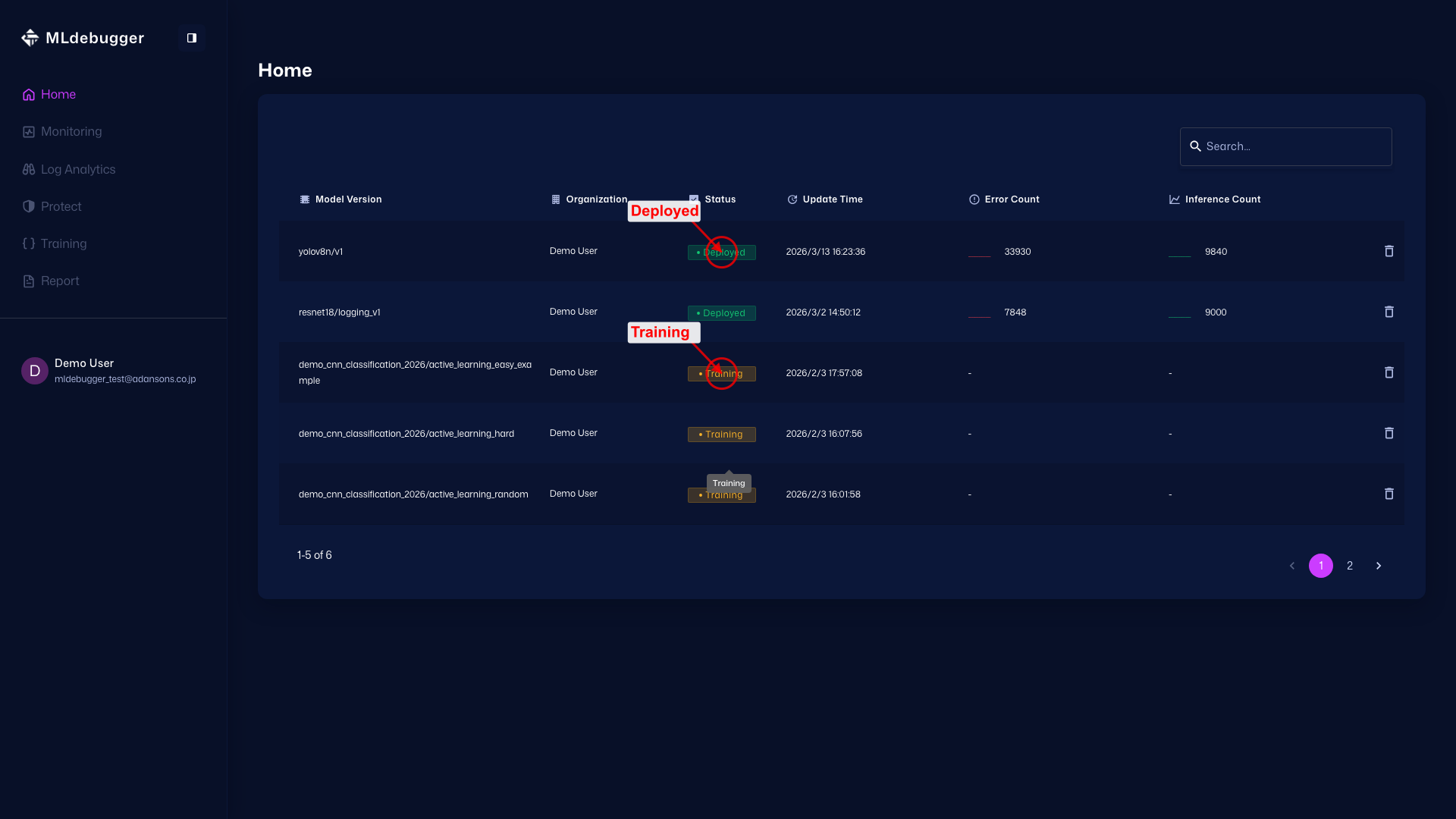
Homeページ
URL: https://app.adansons.ai/home
モデルの状態を確認します。Deployed は GT なし運用で SDK ログ収集が始まっている状態、Training は GT あり評価は完了しているものの GT なし運用ログ収集はまだ始まっていない状態を示します。
-
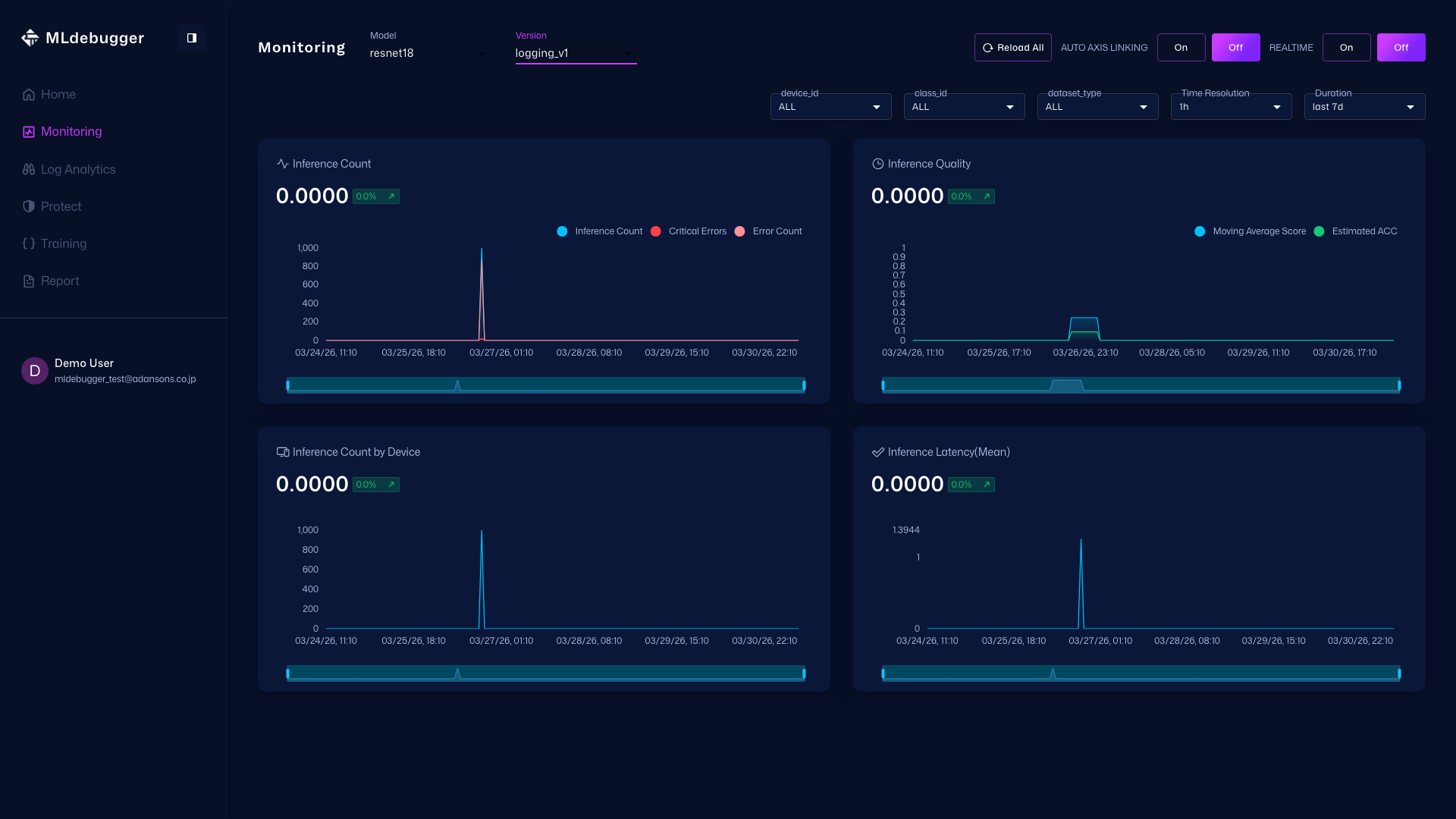
Monitoringページ
URL: https://app.adansons.ai/monitoring
推論数やエラー傾向の変化を確認し、異常の兆候があるかを把握します。
-
Log Analyticsページ
URL: https://app.adansons.ai/log-analytics
Error Map でエラーコードごとの傾向を俯瞰し、Issue List を展開して詳細を確認し、Heatmap で Delta / Count / Error Rate を分析します。
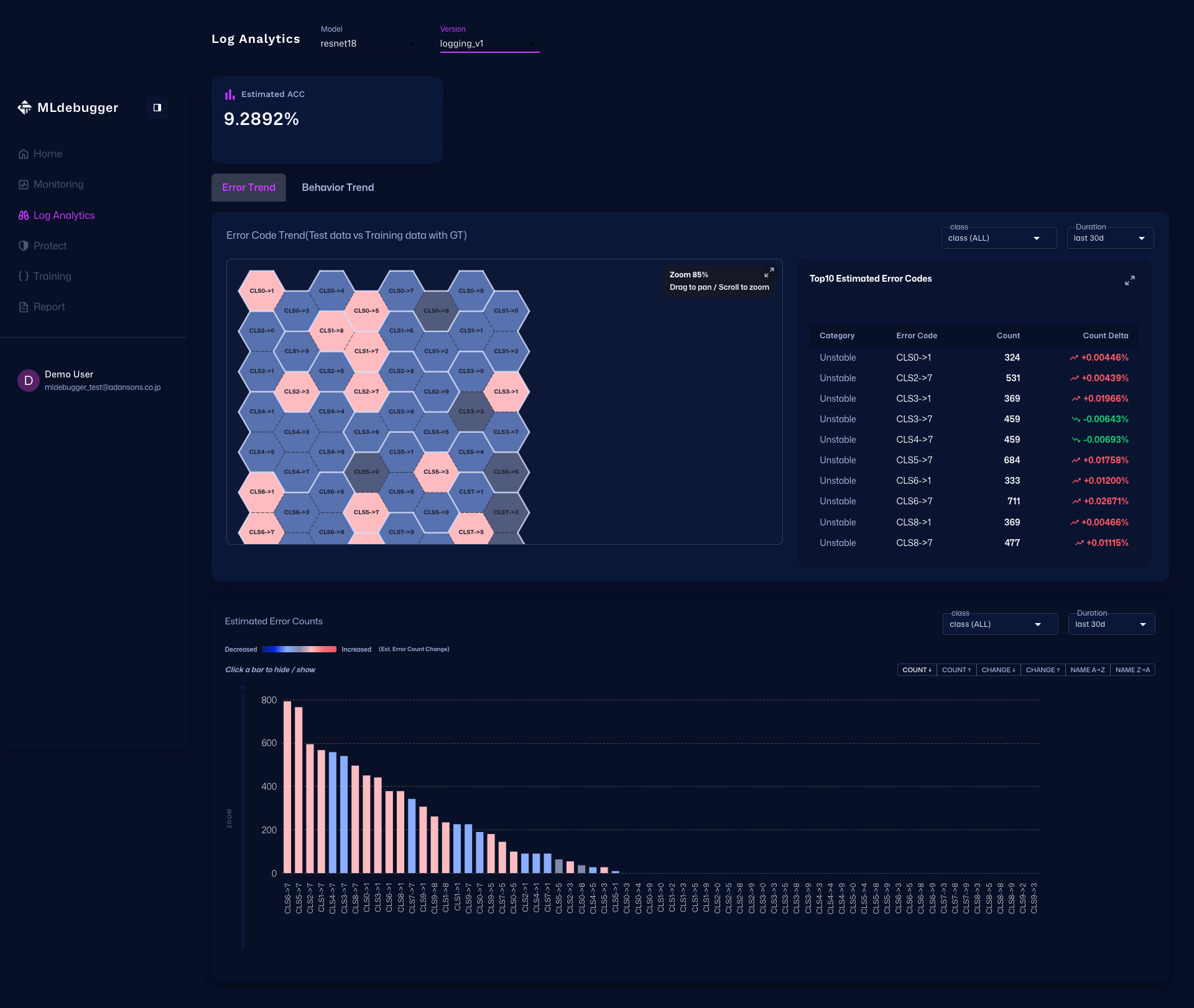
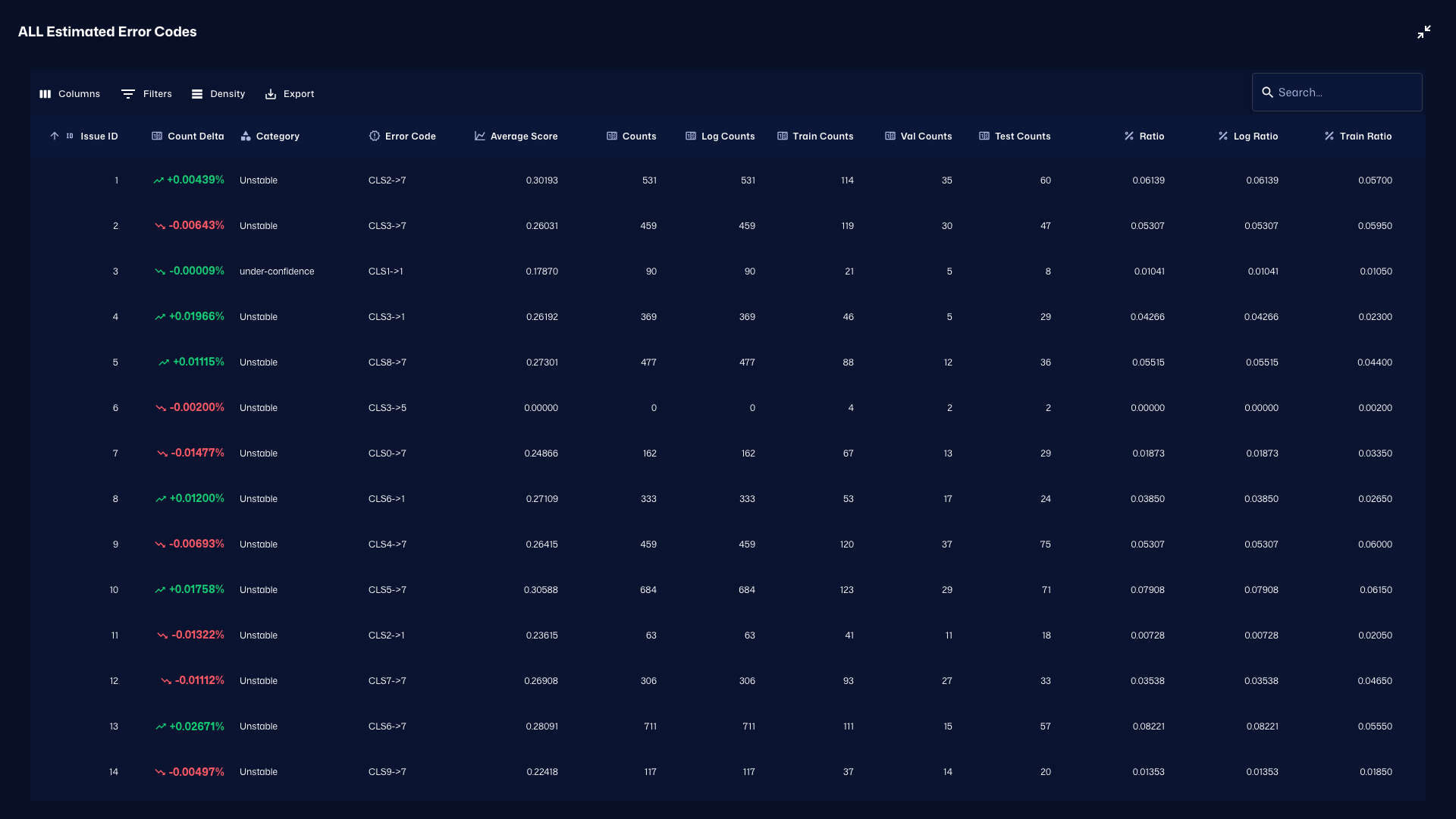
さらに Heatmap タブでは、最初に Delta Heatmap で差分の強い領域を把握し、次に Count Heatmap で件数分布を確認し、最後に Error Rate Heatmap でエラー率の高い領域を確認します。
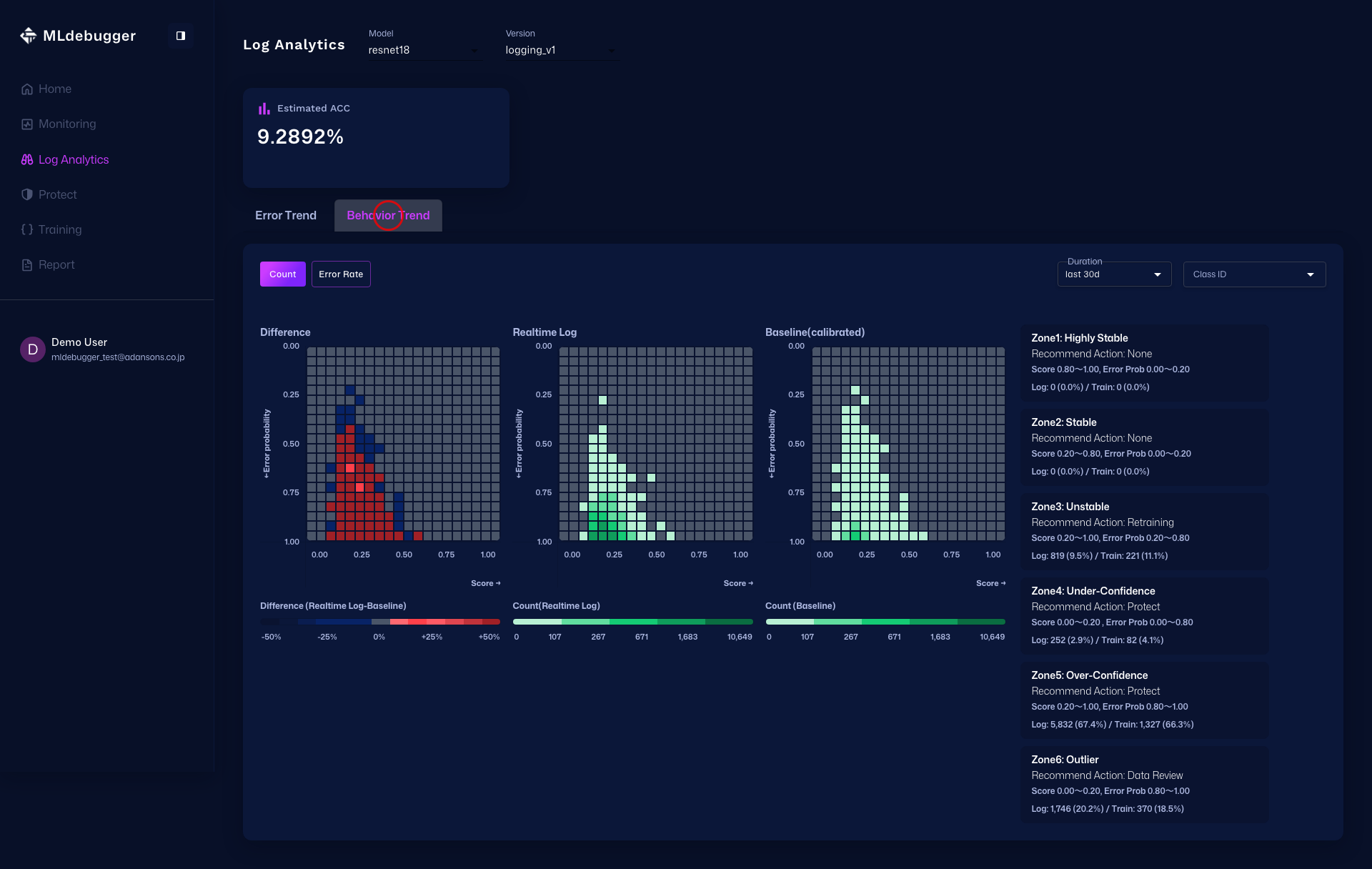
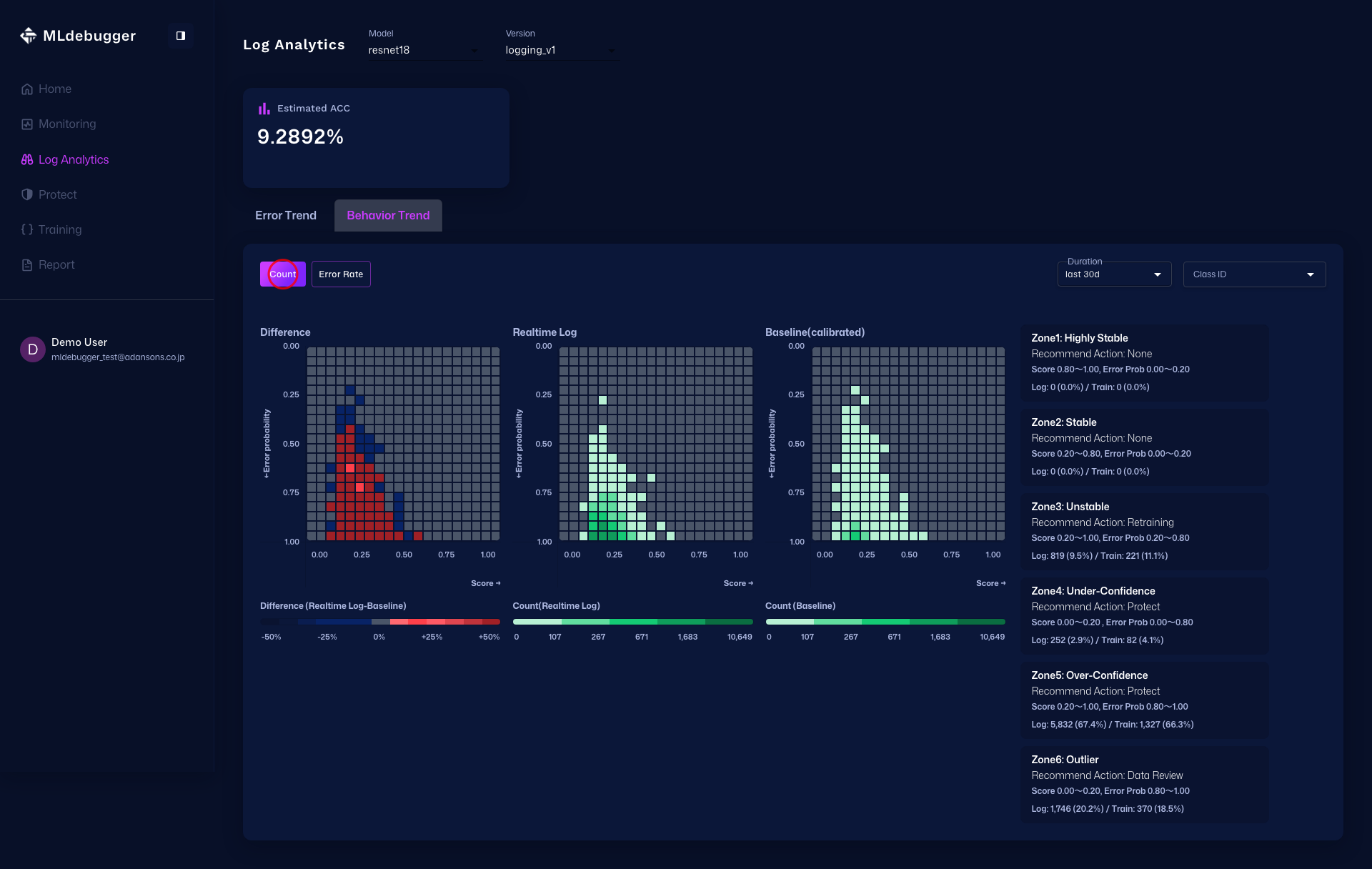
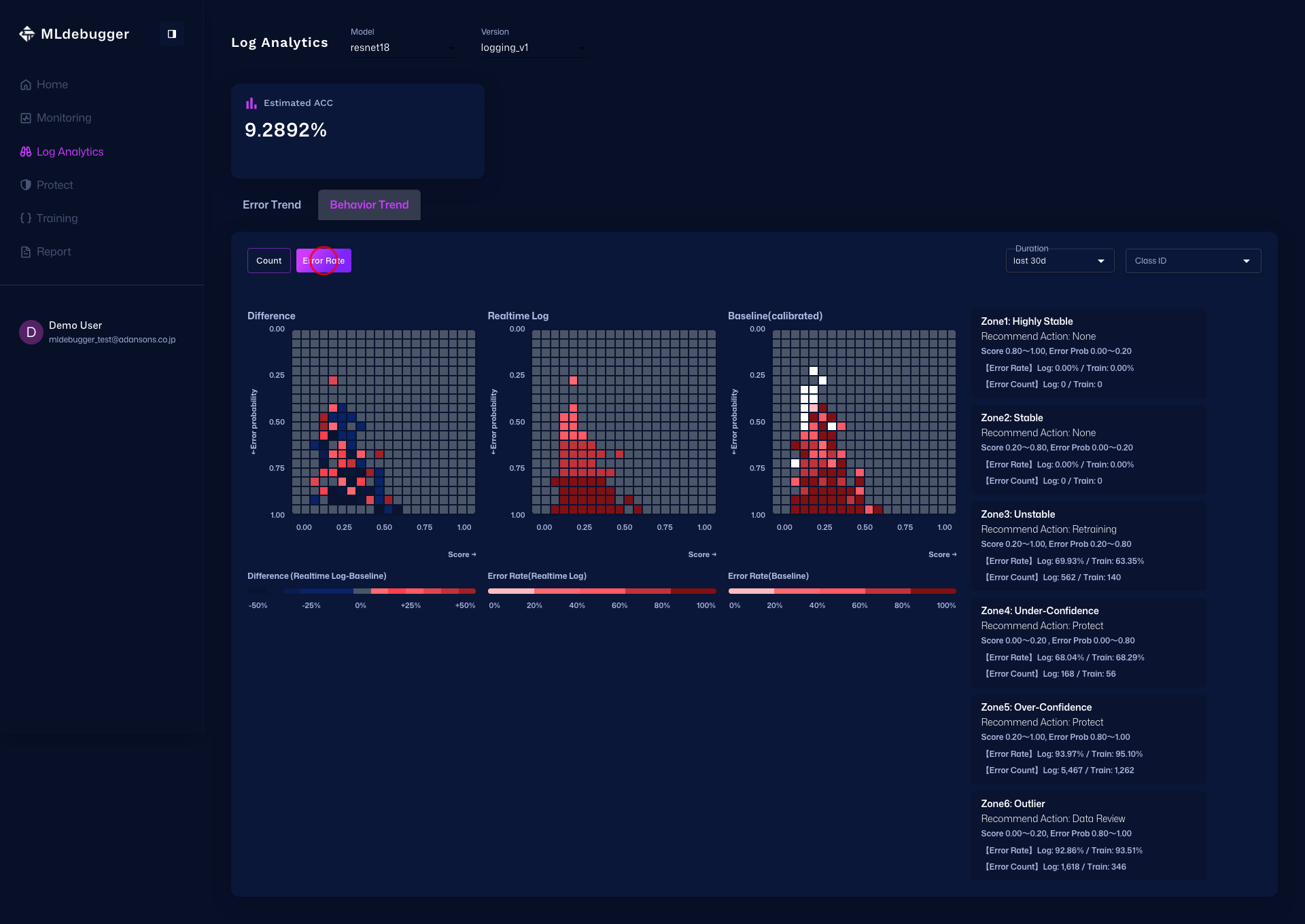
モニタリングで確認できる情報
基本メトリクス(常に利用可能):
- 推論数の推移: 時間帯別の推論リクエスト数
- 統計量: レイテンシ、スループットなど
Error Estimation機能(result_name指定時のみ):
- エラー確率分布: 推論結果のエラー確率の分布
- Issue Category分布: Hotspot、Coverageなどのカテゴリ別分布
- アラート: 異常なパターンの検出と通知
完全なサンプルコード
import os
import torch
from ml_debugger.monitoring import ClassificationLogger
# 認証情報設定
os.environ["MLD_API_ENDPOINT"] = "https://api.adansons.ai"
os.environ["MLD_API_KEY"] = "mldbg_*************"
model = ... # 本番環境のモデル
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# Loggerの初期化
logger = ClassificationLogger(
model,
model_name="my_model",
version_name="v1",
result_name=result.result_name,
)
# 本番環境での推論
for image in production_dataloader:
image = image.to(device)
with torch.no_grad():
predictions = logger(image)
process_predictions(predictions)
import os
import torch
from ml_debugger.monitoring import ObjectDetectionLogger
# 認証情報設定
os.environ["MLD_API_ENDPOINT"] = "https://api.adansons.ai"
os.environ["MLD_API_KEY"] = "mldbg_*************"
model = ... # Object Detectionモデル
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# Loggerの初期化
logger = ObjectDetectionLogger(
model,
model_name="my_od_model",
version_name="v1",
result_name=result.result_name,
)
# 本番環境での推論
for image in production_dataloader:
image = image.to(device)
with torch.no_grad():
predictions = logger(image)
process_predictions(predictions)
import os
import torch
from ml_debugger.monitoring import ObjectDetection3DLogger
# 認証情報設定
os.environ["MLD_API_ENDPOINT"] = "https://api.adansons.ai"
os.environ["MLD_API_KEY"] = "mldbg_*************"
model = ... # 3D Object Detectionモデル
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# Loggerの初期化
logger = ObjectDetection3DLogger(
model,
model_name="my_3d_od_model",
version_name="v1",
result_name=result.result_name,
)
# 本番環境での推論
for points in production_dataloader:
points = points.to(device)
predictions = logger(points)
process_predictions(predictions)
DataFilterとの違い
| 機能 | Logger | DataFilter |
|---|---|---|
| 用途 | 運用時のモニタリング | エラーパターンに基づくデータ選択 |
| ラベル | 不要 | 不要 |
| クエリ機能 | なし | あり |
| Webアプリ連携 | あり | なし |
次のステップ
- Tracing + Evaluation - 基本的なワークフロー
- DataFiltering - エラーパターンに基づくデータ選択・フィルタリング