Tracing + Evaluation
このページでは、MLdebugger SDKを使用してGTありデータセットにおける推論ログデータとアノテーション情報を収集し、評価を実行するワークフローを説明します。
概要
Tracing + Evaluationフローは以下のステップで構成されます:
- 認証情報の設定
- Tracerで推論ログデータとアノテーション情報を収集
- Evaluatorで評価を実行
- Resultで結果を確認
STEP 2で使用するTracerクラスはタスクによって異なります:
| タスク | Tracerクラス |
|---|---|
| Classification | ClassificationTracer |
| Object Detection | ObjectDetectionTracer |
| 3D Object Detection | ObjectDetection3DTracer |
STEP 1: 認証情報の設定
MLdebugger APIに接続するため、環境変数に認証情報を設定します。 API Keyの取得については、認証設定を参照してください。
export MLD_API_ENDPOINT="https://api.adansons.ai"
export MLD_API_KEY="mldbg_*************"
import os
os.environ["MLD_API_ENDPOINT"] = "https://api.adansons.ai"
os.environ["MLD_API_KEY"] = "mldbg_*************"
STEP 2: Tracerでデータ収集
ClassificationTracerを使用して、モデルの推論時に内部特徴量とラベル情報を収集します。
Tracerの初期化
from ml_debugger.training import ClassificationTracer
tracer = ClassificationTracer(
model, # 評価対象のモデル
model_name="resnet18", # モデルの識別子
version_name="v1", # バージョンの識別子
)
データの収集
DataLoaderを使用してバッチ単位でデータを収集します。
import torch
for image, label, indices in dataloader:
image = image.to(device)
label = label.to(device)
with torch.no_grad():
_ = tracer(
image, # 入力データ
label, # 正解ラベル
input_ids=indices.cpu().numpy(), # データの識別子
dataset_type="train", # データセット種別
n_epoch=0, # エポック番号(オプション)
)
データのアップロード
収集したデータをAPIサーバーにアップロードします。
tracer.wait_for_save()
ObjectDetectionTracerを使用して、Object Detectionモデルの推論結果とGround Truthを収集します。
対応モデル:
| フレームワーク | 対応モデル |
|---|---|
| PyTorch | Faster R-CNN, SSD, YOLOv8 (Ultralytics), CenterNet, DETR |
| TensorFlow | KerasCV, TF Object Detection API, Custom Keras |
DETR ファミリーのサポート
DETR (DEtection TRansformer) およびその派生モデル(Conditional DETR, Deformable DETR)に対応しています。
Facebook Research DETRとHuggingFace Transformers DETRの両方を自動検出します。
DETRはNMSを使用しないため、iou_thresh パラメータは無視されます。フィルタリングは score_thresh と max_detections_per_image で制御されます。
Tracerの初期化
from ml_debugger.training import ObjectDetectionTracer
tracer = ObjectDetectionTracer(
model, # PyTorch or TensorFlow OD model
model_name="faster_rcnn", # モデルの識別子
version_name="v1", # バージョンの識別子
score_thresh=None, # NMS スコア閾値(オプション、モデルから自動推定)
iou_thresh=None, # NMS IoU閾値(オプション、モデルから自動推定)
max_detections_per_image=None, # NMS 最大検出数(オプション、モデルから自動推定)
)
ObjectDetectionTracer はファクトリ関数であり、渡されたモデルのフレームワーク(PyTorch / TensorFlow)とアーキテクチャを自動検出して、適切なTracerサブクラスを返します。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
model |
nn.Module / tf.keras.Model |
(必須) | 対象のODモデル |
model_name |
str |
(必須) | モデルの識別子 |
version_name |
str |
(必須) | バージョンの識別子 |
score_thresh |
Optional[float] |
None |
NMSのスコア閾値。未指定時はモデルから自動推定、推定不可の場合は 0.05 |
iou_thresh |
Optional[float] |
None |
NMSのIoU閾値。未指定時はモデルから自動推定、推定不可の場合は 0.5 |
max_detections_per_image |
Optional[int] |
None |
NMS後の最大検出数。未指定時はモデルから自動推定、推定不可の場合は 300 |
データの収集
DataLoaderを使用してバッチ単位でデータを収集します。
import torch
for images, targets, image_ids in dataloader:
images = images.to(device)
_ = tracer(
images, # 入力画像 (B, C, H, W)
targets, # Ground Truth
input_ids=image_ids, # 画像の識別子
dataset_type="train", # データセット種別
n_epoch=0, # エポック番号(オプション)
)
Ground Truthのフォーマット
Ground Truthは以下の2つの形式をサポートしています。
List[Dict] 形式 — 画像ごとに boxes と labels を持つDictのリスト:
ground_truth = [
{
"boxes": torch.tensor([[x1, y1, x2, y2], ...]), # (N, 4)
"labels": torch.tensor([0, 1, ...]), # (N,)
},
... # バッチ内の画像数分
]
Dict[str, List] 形式 — boxes と labels をキーとし、画像ごとのリストを値とするDict:
ground_truth = {
"boxes": [tensor_img1, tensor_img2, ...],
"labels": [tensor_img1, tensor_img2, ...],
}
座標フォーマット
バウンディングボックスは [x1, y1, x2, y2](左上・右下座標)形式で指定してください。
データのアップロード
収集したデータをAPIサーバーにアップロードします。
tracer.wait_for_save()
ObjectDetection3DTracerを使用して、3D Object Detectionモデルの推論結果とGround Truthを収集します。
対応モデル:
| モデル | カテゴリ | モダリティ | 主要フレームワーク |
|---|---|---|---|
| PointPillars | ピラーベース | LiDAR-only | MMDetection3D, OpenPCDet |
| CenterPoint | アンカーフリー中心点ベース | LiDAR-only | MMDetection3D, OpenPCDet |
| BEVFormer | BEV Transformer | Camera-only | MMDetection3D |
| BEVFusion | マルチモーダル融合 | LiDAR+Camera | MMDetection3D, OpenPCDet |
派生モデルのサポート
各モデルは、同一の出力形式を持つ派生モデルもサポートしています:
- PointPillars: PointPillars++, EFMF-Pillars
- CenterPoint: CenterFormer, VoxelNeXt, TransFusion, Voxel R-CNN
- BEVFormer: BEVDet, BEVDet4D, StreamPETR
- BEVFusion: Att-BEVFusion, SAMFusion
BEVFormer ファミリーのサポート
BEVFormerおよびその派生モデルはDETR式のTransformerクエリ出力を使用します。
NMSを使用しないため、iou_thresh パラメータは無視されます。フィルタリングは score_thresh と max_detections_per_frame で制御されます。
Tracerの初期化
from ml_debugger.training import ObjectDetection3DTracer
tracer = ObjectDetection3DTracer(
model, # PyTorch 3D OD model
model_name="centerpoint", # モデルの識別子
version_name="v1", # バージョンの識別子
score_thresh=None, # スコア閾値(オプション、モデルから自動推定)
iou_thresh=None, # BEV IoU閾値(オプション、モデルから自動推定)
max_detections_per_frame=None, # 最大検出数(オプション、モデルから自動推定)
pc_range=[-51.2, -51.2, -5.0, 51.2, 51.2, 3.0], # 点群範囲(BEVFormerで必要、モデルから自動推定可)
)
ObjectDetection3DTracer はファクトリ関数であり、渡されたモデルのアーキテクチャを自動検出して、適切なTracerサブクラスを返します。
input_id / input_hash の設計指針
input_id は「同じ推論設定で同じ結果が返ることを期待する最小単位」を指定してください。3D ODでは通常、1フレーム(1時刻)を1単位にします。
input_hash は同一フレーム内の全モダリティ入力から計算されます。
| パラメータ | 型 | デフォルト | 説明 |
|---|---|---|---|
model |
nn.Module |
(必須) | 対象の3D ODモデル |
model_name |
str |
(必須) | モデルの識別子 |
version_name |
str |
(必須) | バージョンの識別子 |
score_thresh |
Optional[float] |
None |
スコア閾値。未指定時はモデルから自動推定、推定不可の場合は 0.1 |
iou_thresh |
Optional[float] |
None |
BEV IoU閾値。PointPillarsでのみ有効(他モデルはNMS不使用)。未指定時はモデルから自動推定、推定不可の場合は 0.2 |
max_detections_per_frame |
Optional[int] |
None |
フレームあたりの最大検出数。未指定時はモデルから自動推定、推定不可の場合は 300 |
pc_range |
Optional[List[float]] |
None |
点群範囲 [x_min, y_min, z_min, x_max, y_max, z_max]。BEVFormerで必要。未指定時はモデルから自動推定、推定不可の場合はエラー。 |
データの収集
DataLoaderを使用してバッチ単位でデータを収集します。
LiDAR入力(点群テンソル):
import torch
for points, targets, frame_ids in dataloader:
points = points.to(device)
_ = tracer(
points, # 点群 (N, 4+)
targets, # Ground Truth
input_ids=frame_ids, # フレームの識別子
dataset_type="train", # データセット種別
n_epoch=0, # エポック番号(オプション)
)
Dict入力(MMDetection3D形式):
for batch_data in dataloader:
model_input = {
"points": [pts.to(device) for pts in batch_data["points"]],
"img": batch_data["img"].to(device),
"img_metas": batch_data["img_metas"],
}
_ = tracer(
model_input, # Dict形式の入力
batch_data["gt"], # Ground Truth
input_ids=batch_data["frame_ids"],
dataset_type="train",
n_epoch=0,
)
Ground Truthのフォーマット
List[Dict] 形式 — フレームごとに boxes_3d と labels_3d を持つDictのリスト:
ground_truth = [
{
"boxes_3d": torch.tensor([[cx, cy, cz, w, l, h, yaw], ...]), # (N, 7)
"labels_3d": torch.tensor([0, 1, ...]), # (N,)
"velocities": torch.tensor([[vx, vy], ...]), # (N, 2) オプション
},
... # バッチ内のフレーム数分
]
Dict[str, List] 形式 — boxes_3d と labels_3d をキーとし、フレームごとのリストを値とするDict:
ground_truth = {
"boxes_3d": [tensor_frame1, tensor_frame2, ...],
"labels_3d": [tensor_frame1, tensor_frame2, ...],
"velocities": [tensor_frame1, tensor_frame2, ...], # オプション
}
3Dバウンディングボックスフォーマット
3Dバウンディングボックスは [cx, cy, cz, w, l, h, yaw] の7DoF形式で指定してください。
座標はメートル単位、yawはラジアンです。
速度フィールド
CenterPointやBEVFusionなど、速度推定に対応したモデルでは、Ground Truthに velocities フィールド([vx, vy] m/s)を含めることができます。
データのアップロード
収集したデータをAPIサーバーにアップロードします。
tracer.wait_for_save()
n_epochを指定した場合
データ収集時にn_epochを指定した場合は、wait_for_save()にも同じn_epochを渡す必要があります。
tracer.wait_for_save(n_epoch=0)
n_epochの活用
n_epochパラメータを指定することで、エポック別のデータ収集が可能になります。
評価時にn_epoch="latest"を指定すると、最新エポックのデータのみを評価対象にできます。
STEP 3: Evaluatorで評価実行
Evaluatorを使用して、収集したデータに対して評価を実行します。Tracerで指定した model_name と version_name を使用します。
from ml_debugger.evaluator import Evaluator
evaluator = Evaluator(
model_name="<your_model_name>",
version_name="v1",
)
# 評価の実行
result = evaluator.request_evaluation()
request_evaluation()には以下のオプション引数を指定できます:
| 引数 | 型 | デフォルト | 説明 |
|---|---|---|---|
result_name |
Optional[str] |
None |
評価結果のカスタム名。指定しない場合は自動生成されます。 |
n_epoch |
Union[str, int, None] |
"latest" |
評価対象のエポック。"latest"で最新エポック、整数値で特定エポック、Noneで全エポックを対象にします。 |
# 評価結果に名前を指定し、特定のエポックを評価
result = evaluator.request_evaluation(
result_name="my_model_experiment_001",
n_epoch=5,
)
過去の評価結果の取得
# 評価結果一覧の取得
evaluator.list_results()
# 特定の評価結果の取得
result = evaluator.get_result(result_name="<result_name>")
STEP 4: 結果確認
GUIで評価結果を確認
-
Home - 対象モデルを開き、Training 画面へ遷移します。
Home: https://app.adansons.ai/home
Training:https://app.adansons.ai/training
-
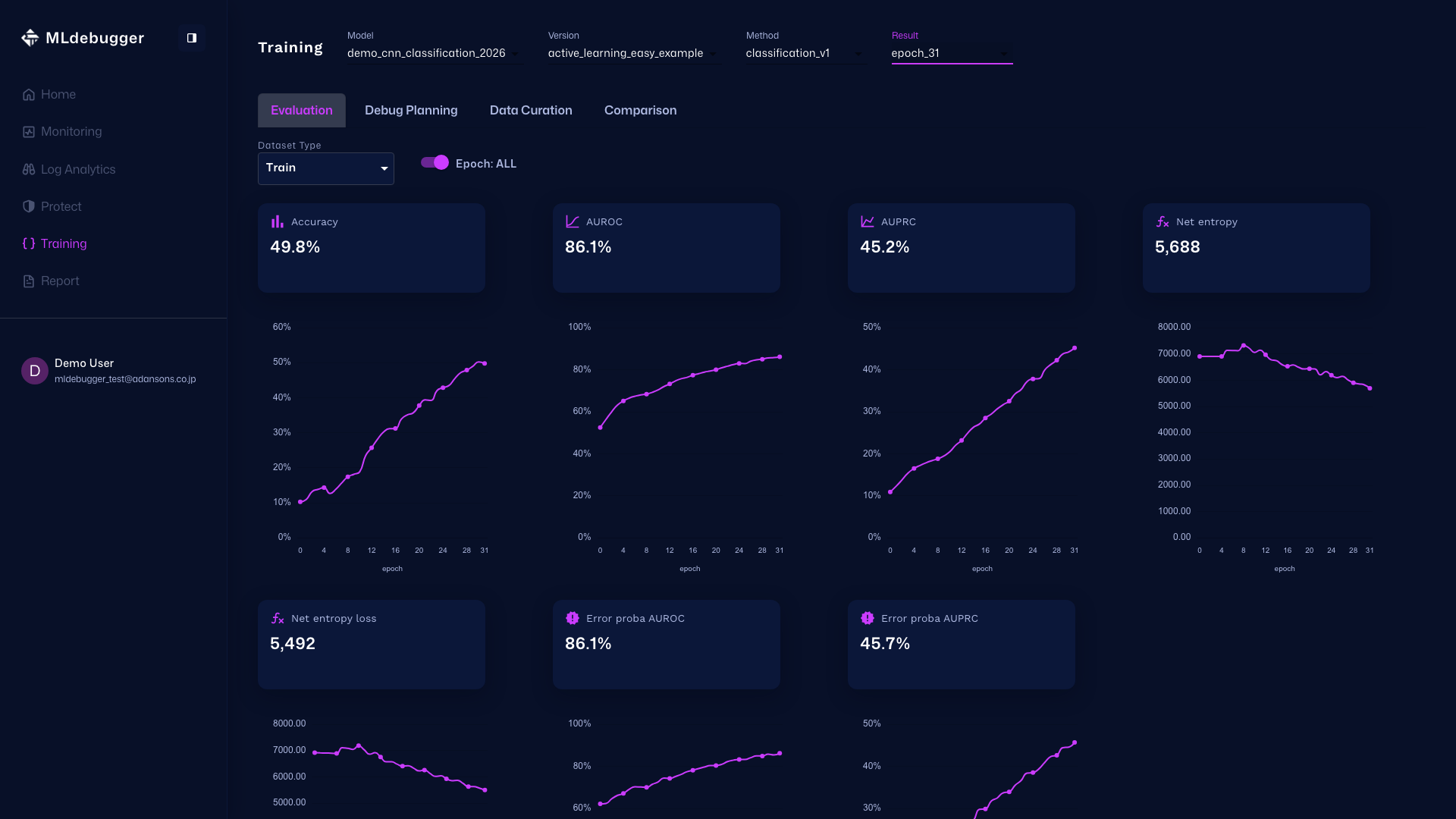
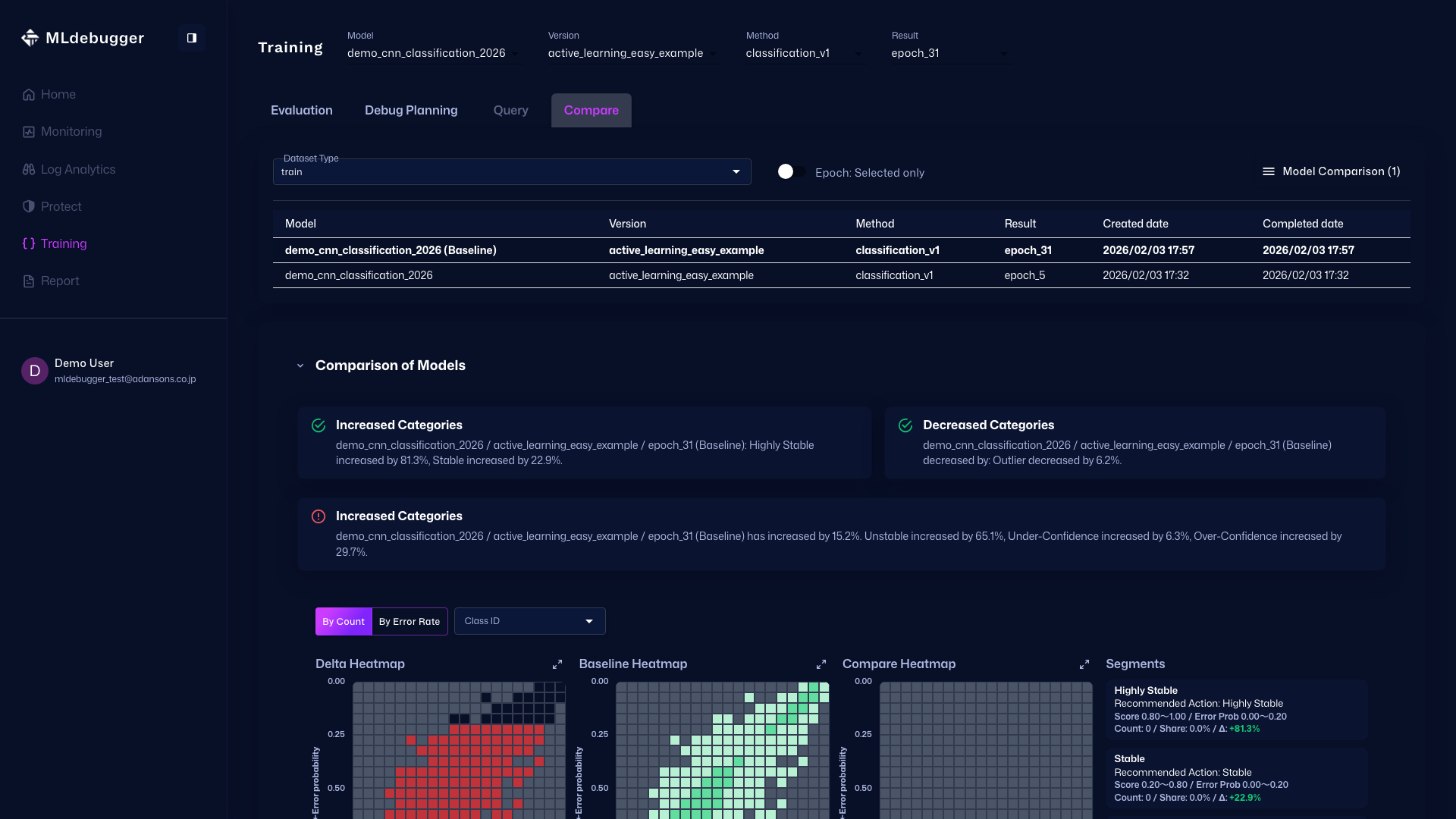
Evaluation with GT - この画面で、評価結果を確認できます。エラーコードやヒートマップでGTありの評価結果を確認し、モデル性能を理解することができます。
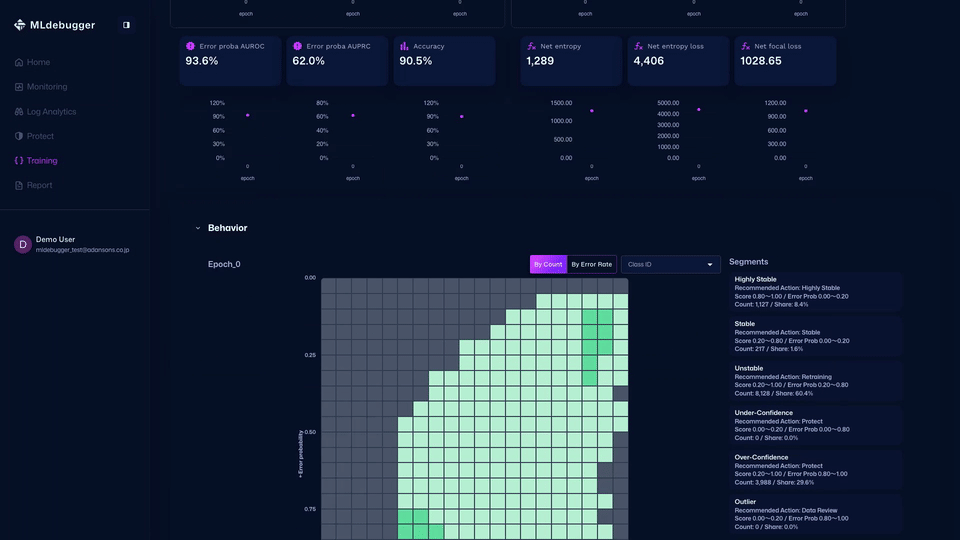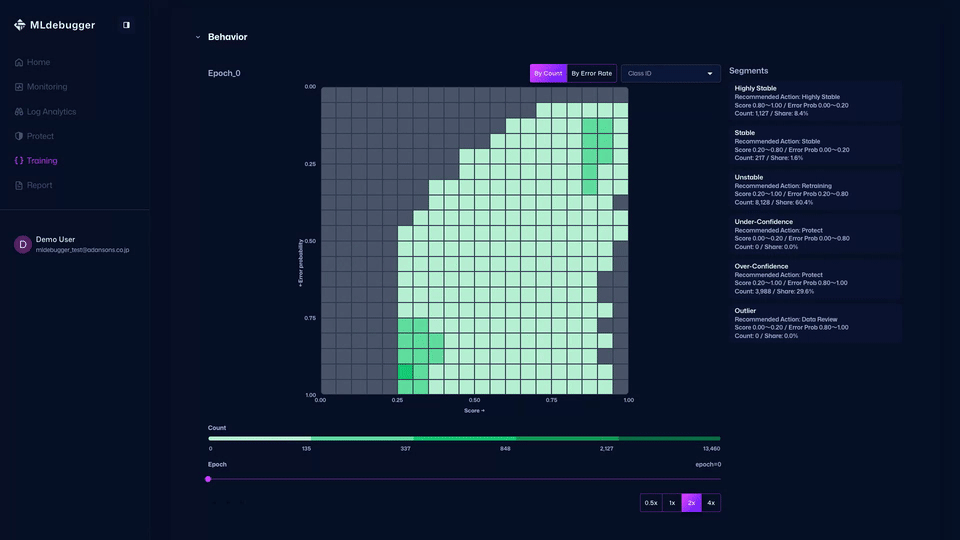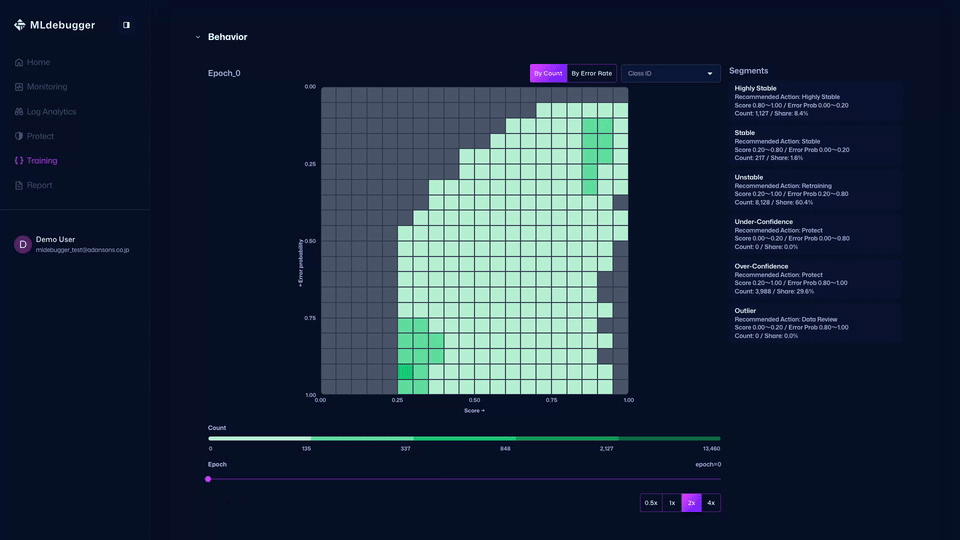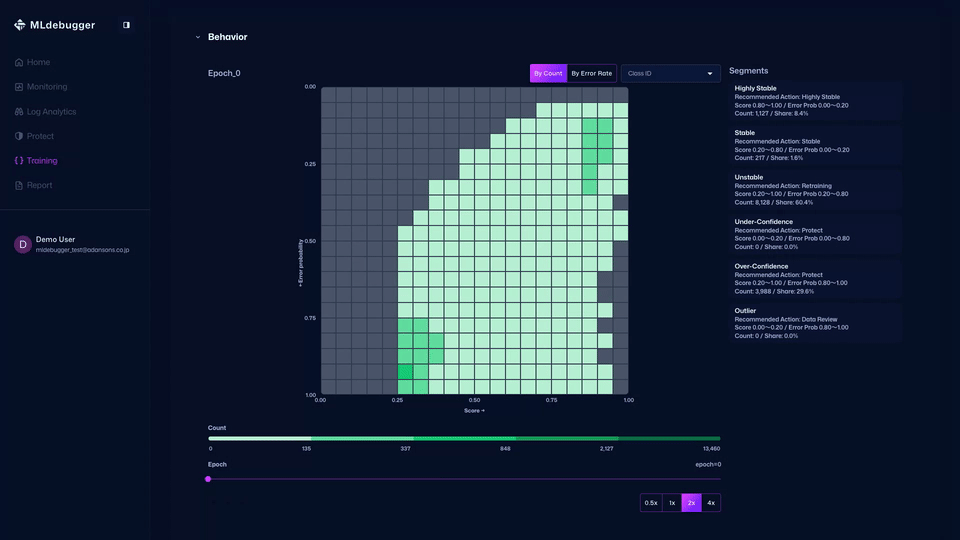
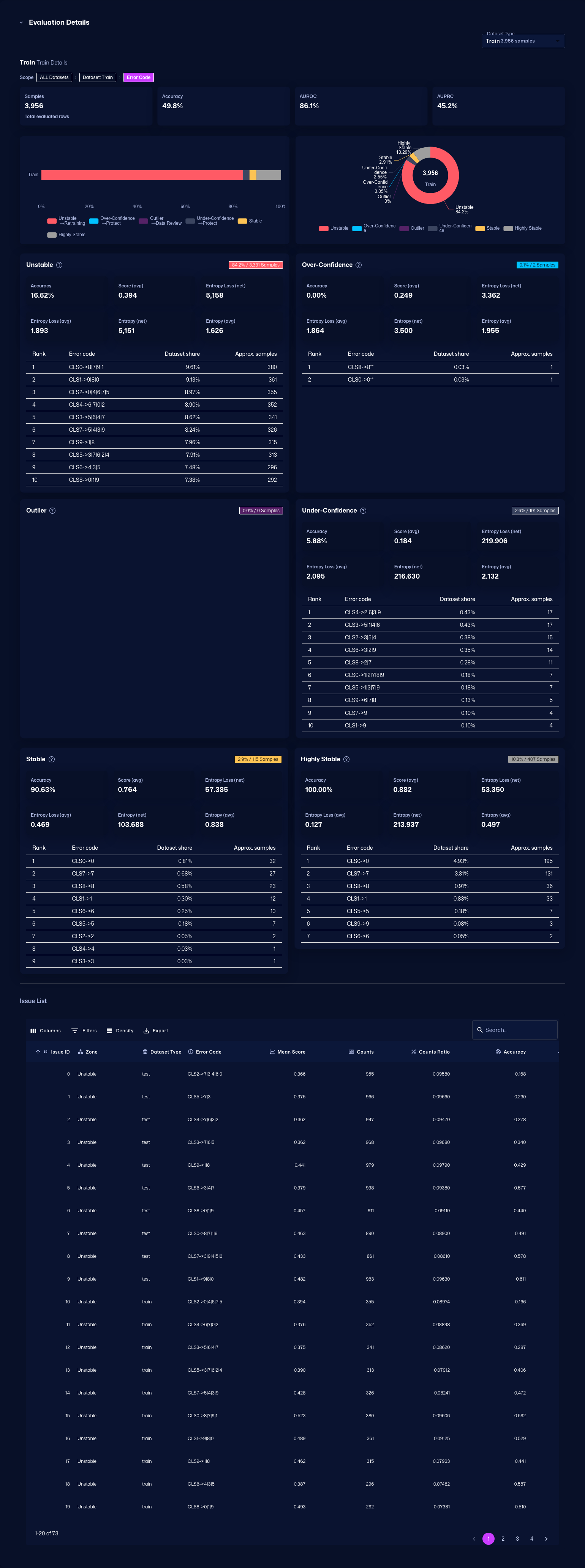
また、カテゴリごとのエラーコード詳細などを確認し、推奨されるデバッグ方法を確認したり、どのようなエラーが多いのかをエラーコードで把握することができます。
-
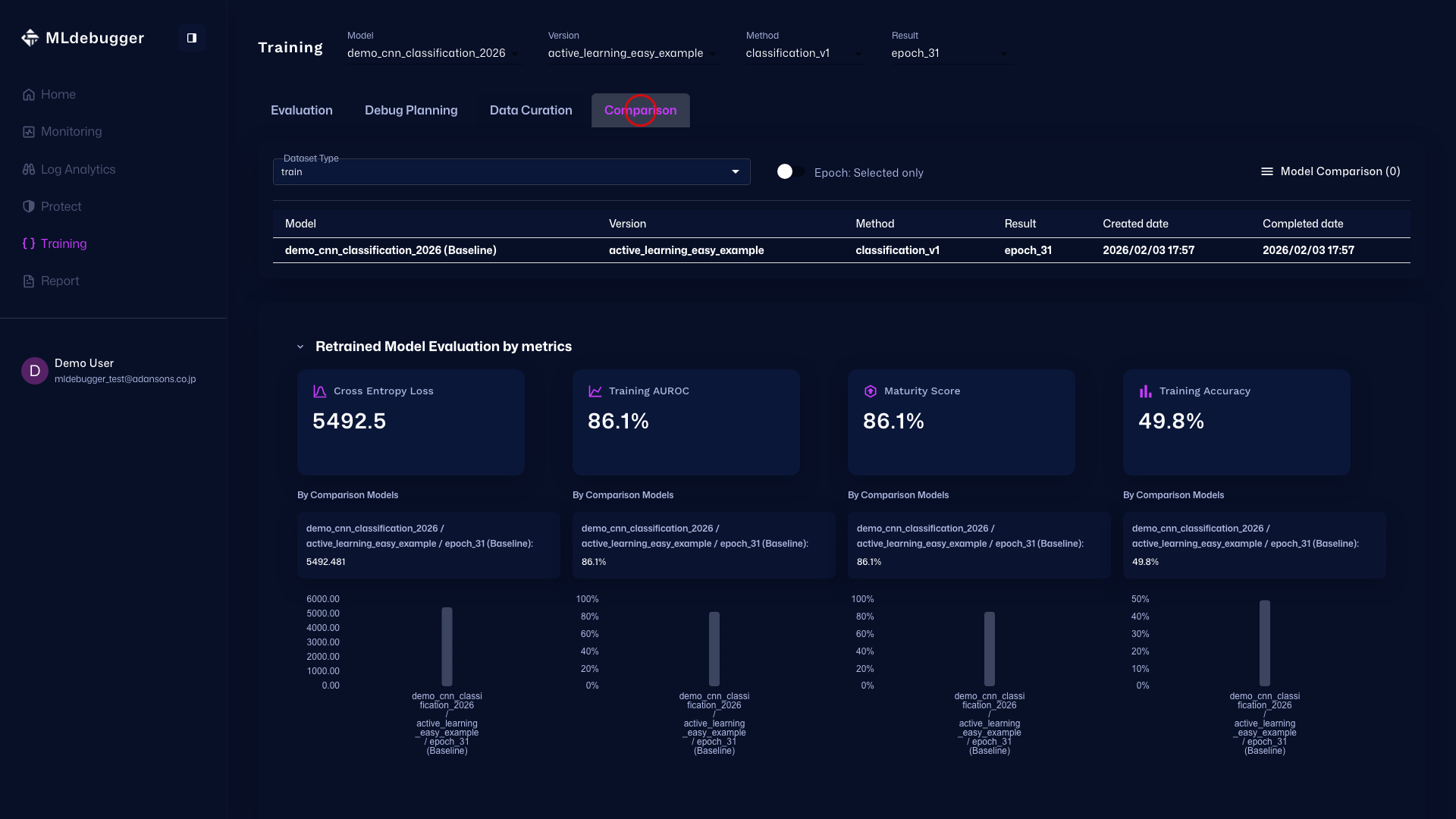
Compare - また、この画面で他のモデルとの比較を行いながら、性能を確認することも可能です。
SDKで評価結果を確認
Resultオブジェクトを使用して、評価結果を確認します。
メトリクスサマリー
print(result.metrics_summary())
出力例:
dataset counts accuracy auroc auprc net_entropy_loss net_entropy error_proba_auroc error_proba_auprc
train 5000 0.098 0.457 0.094 12875.500 10480.190 0.857 0.453
Issue Categoryサマリー
print(result.issue_category_summary())
出力例:
dataset stable_coverage_ratio operational_coverage_ratio hotspot_ratio recessive_hotspot_ratio critical_hotspot_ratio aleatoric_hotspot_ratio
train 0.000 0.001 0.753 0.226 0.019 0.006
詳細サマリー
result.get_summary()
このメソッドは、メトリクス、Issue Category、および各カテゴリの詳細なエラーコード分布を表示します。
Issue一覧の取得
issues_df = result.get_issues()
DataFrameとして全てのIssue(エラーコード)の一覧を取得できます。
カスタムビューの取得
result.get_view(
groupby=["category", "error_code"],
adjustby="category"
)
グループ化やフィルタリングを行ったカスタムビューを取得できます。
完全なサンプルコード
import os
import torch
from ml_debugger.training import ClassificationTracer
from ml_debugger.evaluator import Evaluator
# 認証情報設定
os.environ["MLD_API_ENDPOINT"] = "https://api.adansons.ai"
os.environ["MLD_API_KEY"] = "mldbg_*************"
# モデルとデータローダーの準備(ユーザー側で実装)
model = ... # 学習済みモデル
dataloader = ... # DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# Tracerの初期化
tracer = ClassificationTracer(
model,
model_name="my_model",
version_name="v1",
)
# データ収集
for image, label, indices in dataloader:
image = image.to(device)
label = label.to(device)
with torch.no_grad():
_ = tracer(image, label, input_ids=indices.cpu().numpy(), dataset_type="train")
# アップロード
tracer.wait_for_save()
# 評価実行
evaluator = Evaluator(model_name="my_model", version_name="v1")
result = evaluator.request_evaluation()
# 結果確認
result.get_summary()
import os
import torch
from ml_debugger.training import ObjectDetectionTracer
from ml_debugger.evaluator import Evaluator
# 認証情報設定
os.environ["MLD_API_ENDPOINT"] = "https://api.adansons.ai"
os.environ["MLD_API_KEY"] = "mldbg_*************"
# モデルとデータローダーの準備(ユーザー側で実装)
model = ... # Object Detection モデル (e.g. Faster R-CNN, SSD, YOLOv8, DETR)
dataloader = ... # DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# Tracerの初期化
tracer = ObjectDetectionTracer(
model,
model_name="my_od_model",
version_name="v1",
)
# データ収集
for images, targets, image_ids in dataloader:
images = images.to(device)
_ = tracer(
images,
targets,
input_ids=image_ids,
dataset_type="train",
)
# アップロード
tracer.wait_for_save()
# 評価実行
evaluator = Evaluator(model_name="my_od_model", version_name="v1")
result = evaluator.request_evaluation()
# 結果確認
result.get_summary()
import os
import torch
from ml_debugger.training import ObjectDetection3DTracer
from ml_debugger.evaluator import Evaluator
# 認証情報設定
os.environ["MLD_API_ENDPOINT"] = "https://api.adansons.ai"
os.environ["MLD_API_KEY"] = "mldbg_*************"
# モデルとデータローダーの準備(ユーザー側で実装)
model = ... # 3D Object Detection モデル (e.g. CenterPoint, PointPillars, BEVFormer, BEVFusion)
dataloader = ... # DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# Tracerの初期化
tracer = ObjectDetection3DTracer(
model,
model_name="my_3d_od_model",
version_name="v1",
)
# データ収集
for points, targets, frame_ids in dataloader:
points = points.to(device)
_ = tracer(
points,
targets,
input_ids=frame_ids,
dataset_type="train",
)
# アップロード
tracer.wait_for_save()
# 評価実行
evaluator = Evaluator(model_name="my_3d_od_model", version_name="v1")
result = evaluator.request_evaluation()
# 結果確認
result.get_summary()
次のステップ
- DataFiltering - Active Learningのためのデータ選択
- Logging - 運用時の推論ログ収集
- model_name / version_name - 識別子の詳細な説明
- Evaluation と Result - 評価の詳細設定